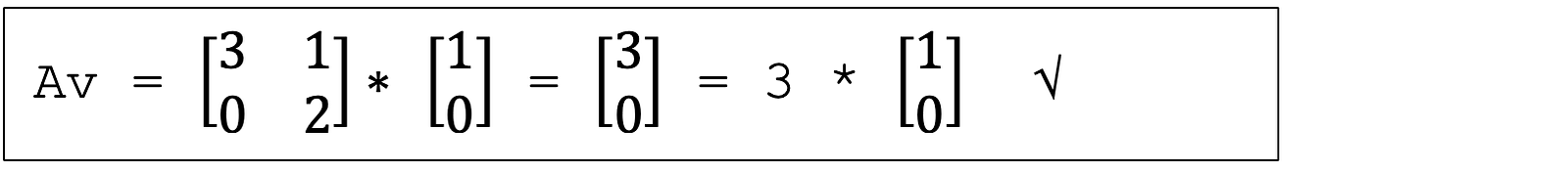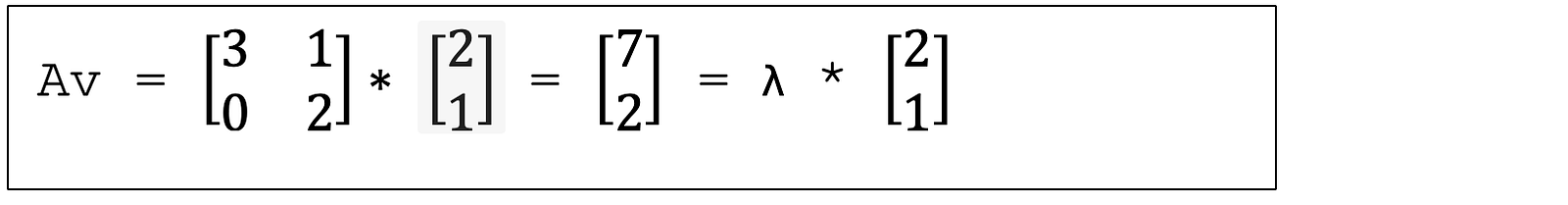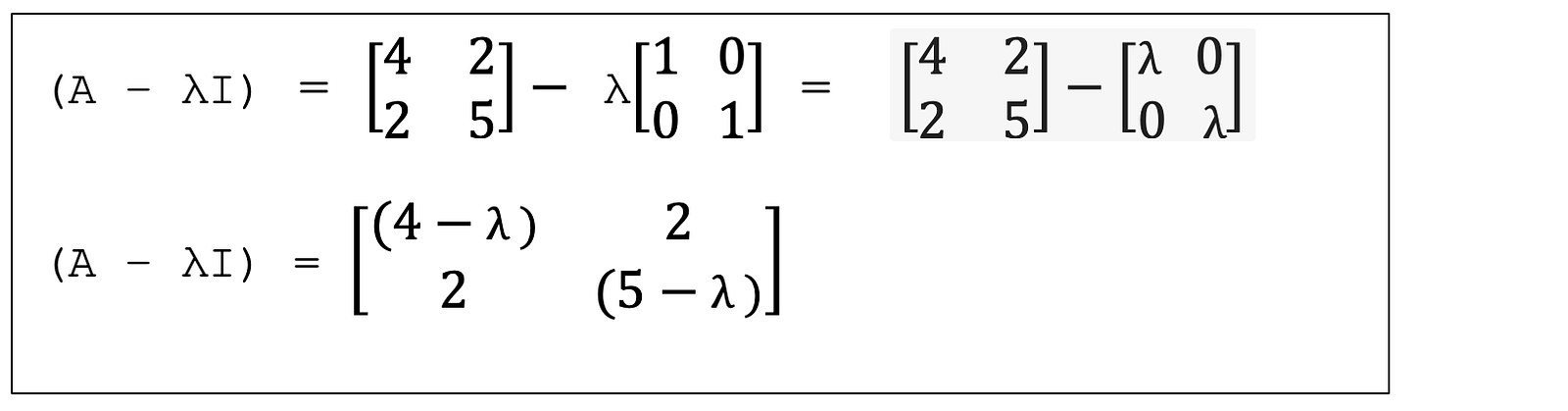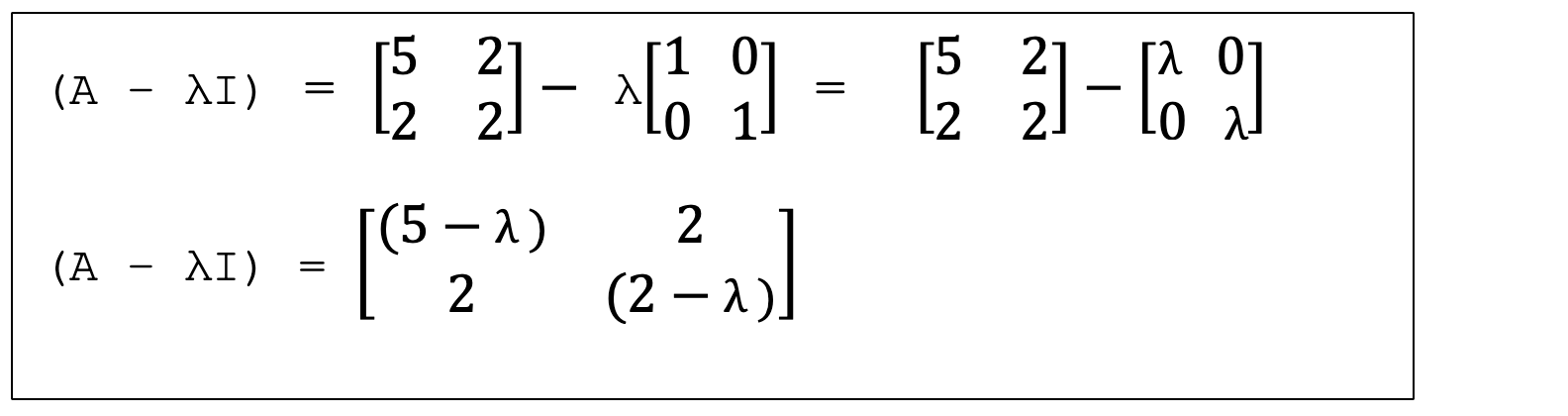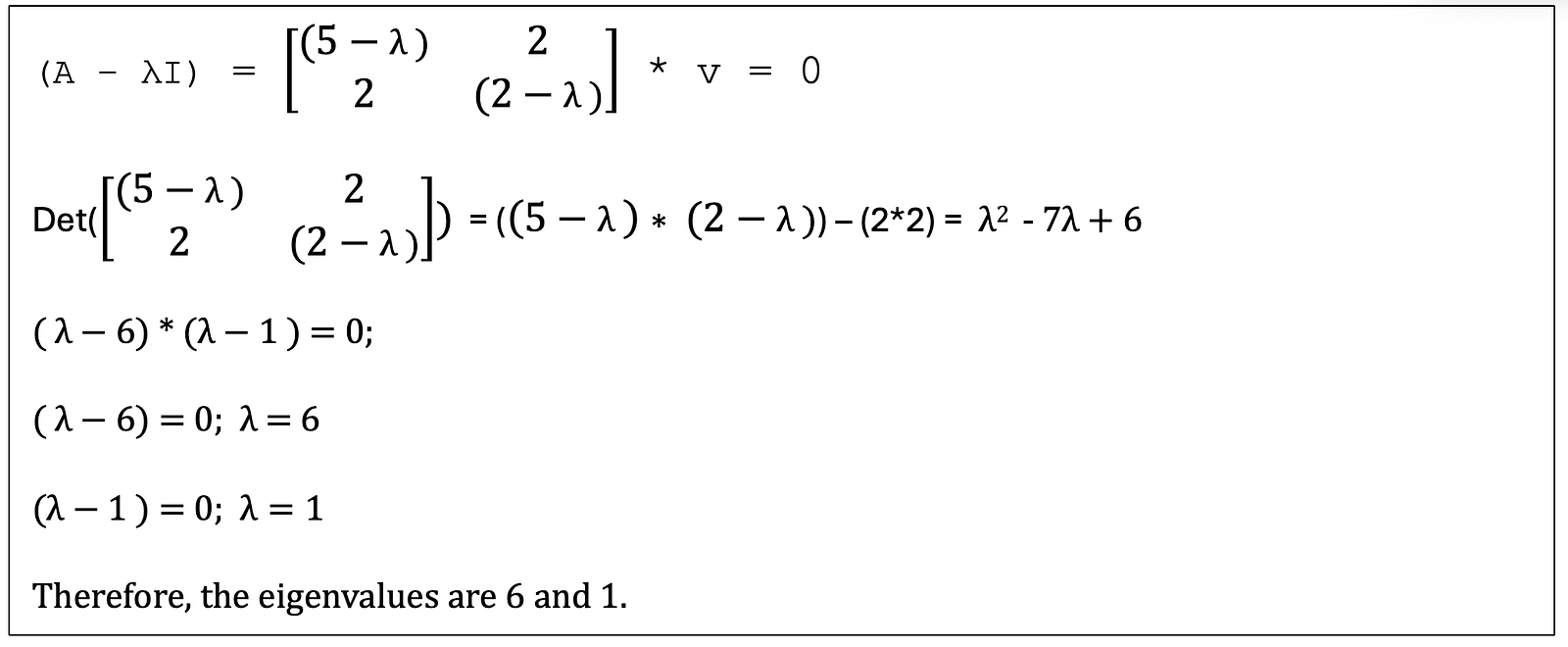Part 5. Eigenvalue Spectra
Eigenvalue spectra reveal crucial information about neural network behavior, training dynamics, and generalization.
Here is only a first exposure to this concept. There will be more detailed articles soon.
Nonetheless, a very simple bit of code can also give a rudimentary understanding of the nature and practical use of eigenvalues.
In the following code, we obtain the weight matrix from a layer in our neural network. We want to evaluate that layer and understand how it contributes to the whole network, so we obtain the eigenvalues, and from these we obtain the spectrum of sorted eigenvalues.
import torch
import numpy as np
layer = model.layers[0]
W = layer.weight.detach().cpu().numpy()
eigenvalues = np.linalg.eigvals(W @ W.T)
spectrum = np.sort(np.abs(eigenvalues))[::-1]
print(f"Spectral norm (largest eigenvalue): {spectrum[0]:.4f}")
print(f"Condition number: {spectrum[0] / spectrum[-1]:.4f}")
How do we interpret these values? Again, this is just an exposure to the topic. But here are some principles:
- A large spectral norm (>1) suggests that this layer amplifies signals and can lead to potential exploding gradients.
- A small spectral norm (<1) suggests that this layer dampens signals and can lead to potential vanishing gradients.
- A high condition number suggests numerical instability, because it shows that some directions have learned much better than others.
- A large number of near-zero eigenvalues suggests rank collapse will or did happen: This is where the entire layer is using only a few dimensions.
Part 6. Analyze The Network
Even with small model networks, we can perform simple analyses that will help improve our outcomes.
Below find a simple python snippet that we can use to look at our own experimental networks, followed by some explanation of how to interpret the results.
def diagnose_network_health(model, train_loader):
"""Comprehensive eigenvalue analysis"""
"""
Parameters:
-----------
model : torch.nn.Module
A PyTorch neural network model
train_loader : torch.utils.data.DataLoader
A PyTorch DataLoader that provides batches of (inputs, labels)
"""
print("="*50)
print("NEURAL NETWORK EIGENVALUE ANALYSIS")
print("="*50)
print("\n1. WEIGHT MATRICES:")
for name, param in model.named_parameters():
if 'weight' in name and len(param.shape) == 2:
W = param.detach().cpu().numpy()
analyze_weight_spectrum(W, name)
print("\n2. GRADIENT COVARIANCE:")
grad_spectrum = analyze_gradient_covariance(model, train_loader)
print("\n3. LOSS LANDSCAPE (Hessian):")
print("\n4. NEURAL COLLAPSE:")
print("\n" + "="*50)
To use the ‘diagnose_network_health()’ function, we need the following:
<strong class="markup--strong markup--li-strong">model</strong> must be an instance of torch.nn.Module or a subclass<strong class="markup--strong markup--li-strong">train_loader</strong> must be a torch.utils.data.DataLoader that yields (inputs, labels) tuples
We can create a DataLoader from NumPy arrays (via TensorDataset), existing datasets (torchvision.datasets, torchtex)and other methods.
What Different Patterns Mean
When all weight eigenvalues are near 1, our network is well-normalized and stable — this is good!
If some weight eigenvalues are much greater than 1, we risk gradient explosion and should consider adding spectral normalization.
When many eigenvalues approach zero, we are experiencing dimensional collapse and may need wider layers or regularization.
If the Hessian has few large eigenvalues, we are in a sharp minimum and should reduce our learning rate.
When the Hessian has many small eigenvalues, we’re in a flat minimum, which is good for generalization!
If the gradient covariance has a concentrated spectrum, we have low-rank learning — this is normal, but watch for training stagnation.
Conclusions
This is a lot of information. We’ve gone from calculating an eigenvector, and eigenvalue to using these concepts to evaluate our real networks. But the main point here is that we need to know how to calculate eigenvectors and eigenvalues. The tools that use this math will be learned more deeply in subsequent articles.